CATMA: Unterschied zwischen den Versionen
(→Allgemeine Voraussetzungen) |
|||
| Zeile 1: | Zeile 1: | ||
| − | '''Achtung: Hier entsteht ein Eintrag zu CATMA. Alle Inhalte sind | + | '''Achtung: Hier entsteht ein Eintrag zu CATMA. Alle Inhalte sind noch vorläufiger Natur! :)'''' |
| + | |||
| + | == '''Kurzbeschreibung des Tools''' == | ||
| + | |||
| + | CATMA steht für ''Computer Aided Textual Markup and Analysis''. Es handelt sich dabei um ein Annotations- und Analysetool im Zeichen der empirischen Literaturwissenschaft. CATMA wurde für die literaturwissenschaftliche Analyse von Einzeltexten entwickelt und richtet sich speziell an Anwender mit wenig oder keinen Programmierkenntnissen. | ||
| + | |||
| + | Es kann in der aktuellen Version [http://www.catma.de/ CATMA 3.2] kostenfrei heruntergeladen werden. | ||
| + | |||
| + | Die Software wird von einem Entwicklerteam an der Universität Hamburg laufend gewartet und weiterentwickelt. Der Projektleiter [http://www.slm.uni-hamburg.de/ifg2/personal/jan-christoph-meister.html Jan Christoph Meister] beschreibt das Arbeiten mit CATMA folgendermaßen: | ||
| + | |||
| + | : CATMA's workflow tries to emulate that of a traditional literary scholar who reads a text, makes some annotations, compares and analyses the notes and then uses these results to interpret the text. [...] CATMA must also pay tribute to one of the key methodological tenets of literary scholarship: the principal open-endedness of any research into the semantics of literary texts. | ||
| + | : (aus dem Vorwort des CATMA Handbuchs, Schüch 2010). | ||
| + | |||
| + | Mit CATMA lassen sich Texte über Tags annotieren und in einem nächsten Arbeitsschritt bestimmte statistische Analysen über diese Annotationen auf einer intuitiv bedienbaren Benutzeroberfläche oder - abhängig von den Programmierkenntnissen des Anwenders - mithilfe eigener Anfragen rechnen. | ||
| + | |||
== '''Allgemeine Voraussetzungen''' == | == '''Allgemeine Voraussetzungen''' == | ||
| Zeile 5: | Zeile 19: | ||
*Technische Voraussetzungen: Mac/Windows Betriebssystem und eine aktuelle JAVA-Version | *Technische Voraussetzungen: Mac/Windows Betriebssystem und eine aktuelle JAVA-Version | ||
*Aktuelle Version: [http://www.catma.de/download CATMA 3.2] | *Aktuelle Version: [http://www.catma.de/download CATMA 3.2] | ||
| − | + | *Installationssoftware für Mac und Windows (JAVA basiert) | |
| − | *Installationssoftware für Mac und Windows (JAVA | + | |
*kostenfreie Nutzung ohne Registrierung | *kostenfreie Nutzung ohne Registrierung | ||
| − | * | + | *bearbeitet Dateien der Endung .txt, .doc, .pdf, .html, .htm und .rtf |
| − | *Nutzbar für Texte in über 45 Sprachen ([http://en.wikipedia.org/wiki/Part_of_speech | + | *Nutzbar für Texte in über 45 Sprachen ([http://en.wikipedia.org/wiki/Part_of_speech Part of Speech]-Trennung) |
| − | *Alle Ergebnisse können im .rtf-Format gespeichert werden | + | *Alle Ergebnisse können im .rtf-Format gespeichert werden |
| + | *Aufrufen von Hilfeseiten während der Bearbeitung möglich | ||
| + | *keine Programmierkenntnisse erforderlich | ||
| + | |||
| + | |||
| + | == '''Detaillierte Beschreibung des Tools''' == | ||
| + | |||
| + | Obwohl mit CATMA Kollokationsanalysen und Wortlisten generiert werden können, lebt das Tool von der händischen Annotation und der Expertise des Literaturwissenschaftlers, der sein Wissen an den Text heranträgt. In dieser Hinsicht ist es vergleichbar beispielsweise mit [[Scheherazade]], das ebenfalls einen Fokus auf die qualitative Textanalyse legt. CATMA ist gleichzeitig allerdings in der Lage, statistische Analysen über händische Annotationen durchzuführen. Darin unterscheidet sich CATMA von den anderen in diesem Wiki vorgestellten Tools. Die drei interaktiven Komponenten des Tools sind<ref>www.catma.de/functionality</ref>: | ||
| + | |||
| + | *CATMA Tagger | ||
| + | *CATMA Analyzer | ||
| + | *Query Builder | ||
| + | |||
| + | ==='''Arbeitsschritte'''=== | ||
| + | |||
| + | Meine Beschreibung der einzelnen Arbeitsschritte in CATMA folgt in weiten Teilen dem englischsprachigen [http://www.catma.de/webfm_send/7 CATMA-Handbuch] von Lena Schüch. Die Screenshots dienen nur der Illustration und zeigen die Mac-Distribution, ggf. kann sich die Oberfläche in Windows etwas anders darstellen. | ||
| + | |||
| + | : [[Datei:Start_Frame.png|250px|thumb|left|Startbildschirm des CATMA Taggers]] | ||
| + | |||
| + | *'''Texteinspeisung: Das ''Source Document''''' | ||
| + | : Um einen Text einzuspeisen, klickt man den Button ''Open Source File''. Es lässt sich jede Datei mit einer der oben genannten Endungen von der Festplatte aus laden. Gleich darauf öffnet sich ein Dialogfenster, das den Nutzer bittet, eine mit dem Quelldokument assoziierte ''Structure Markup File'' zu öffnen oder erstellen zu lassen. | ||
| + | |||
| + | : Es können Einzeltexte mit den Endungen .doc, .txt, .pdf, .html, .htm und .rtf eingespeist werden. | ||
| + | |||
| + | *'''Eine Structure Markup File erstellen''' | ||
| + | |||
| + | : [[Datei:Create_New_Structure_Markup.png|250px|thumb|left|Eine neue ''Structure Markup''-Datei anlegen]] | ||
| + | |||
| + | : In einem weiteren Schritt bittet CATMA den Benutzer, ein ''Structure Markup Document'' auszuwählen oder generieren zu lassen. In diesem Dokument speichert CATMA metatextuelle Informationen wie das Dateiformat, Textkodierung und die Sprache. Die ''Structure Markup''-Datei erstellt CATMA automatisch, wenn an dieser Stelle "Create a new document" ausgewählt wird. Weiter wird CATMA dem ausgewählten Text in einem neuen Fenster ein Kodierungsformat zuweisen. Ob das Format richtig zugeordnet wurde, lässt sich überprüfen, indem man die Vorschau auf ausgetauschte Symbole durchsucht. Wird der Text korrekt angezeigt, hat CATMA das Textformat und die Kodierung richtig erkannt. Beides lässt sich auch manuell anpassen. | ||
| + | |||
| + | : [[Datei:Choose_Language.png|250px|thumb|right|Sprache des Quelltextes festlegen]] | ||
| + | |||
| + | : In einem nächsten Schritt fragt CATMA nach der Sprache des Textes. Es lassen sich über 45 verschiedene Sprachen auswählen. Die Auswahl hilft CATMA, Wortarten korrekt zu trennen; beispielsweise sollte in einem englischsprachigen Text ''you'll'' als Kontraktion aus zwei Wörtern erkannt werden. Dazu lässt sich hier festlegen, wie CATMA das Apostroph behandeln soll. Weiter können manuell solche Einträge festgelegt werden, die nie getrennt dargestellt werden sollen. Es ist wichtig zu beachten, dass diese Auswahl sich nur ein Mal zu Beginn festlegen lässt und später nicht widerrufen oder verändert werden kann. Eine automatische POS-Erkennung liefert CATMA nicht. | ||
| + | |||
| + | : Optional kann dem Text danach Informationen zum Titel, Autor, Herausgeber und eine Beschreibung beigefügt werden. Zum Schluss fragt CATMA nach der Textsorte und bittet den Benutzer, zwischen ''Prose'', ''Drama'' und ''Speech'' auszuwählen. Die ''Structure Markup''-Datei spielt im weiteren Annotations- und Analyseprozess keine Rolle und wird automatisch gespeichert, wenn zum Schluss ''Create User Markup File'' angeklickt wird. | ||
| + | |||
| + | *'''Eine User Markup File erstellen''' | ||
| + | : Die ''User Markup File'' ist die Datei, in der CATMA Annotationen am Text speichert. So bleiben Markup und Originaltext getrennt und der Text wird im Analyseprozess nicht verändert. Das spielt besonders dann eine Rolle, wenn mehrere Parteien gleichzeitig an verschiedenen Markups zu einem Text arbeiten. Außerdem ist es so auch möglich, verschiedene Markup-Dateien mit einem Textdokument zu assoziieren, um den Überblick über die eigene Textarbeit zu behalten. Der Name des Markup-Dokuments kann dazu jeweils angepasst werden. | ||
Version vom 24. Februar 2012, 11:58 Uhr
Achtung: Hier entsteht ein Eintrag zu CATMA. Alle Inhalte sind noch vorläufiger Natur! :)'
Inhaltsverzeichnis
Kurzbeschreibung des Tools
CATMA steht für Computer Aided Textual Markup and Analysis. Es handelt sich dabei um ein Annotations- und Analysetool im Zeichen der empirischen Literaturwissenschaft. CATMA wurde für die literaturwissenschaftliche Analyse von Einzeltexten entwickelt und richtet sich speziell an Anwender mit wenig oder keinen Programmierkenntnissen.
Es kann in der aktuellen Version CATMA 3.2 kostenfrei heruntergeladen werden.
Die Software wird von einem Entwicklerteam an der Universität Hamburg laufend gewartet und weiterentwickelt. Der Projektleiter Jan Christoph Meister beschreibt das Arbeiten mit CATMA folgendermaßen:
- CATMA's workflow tries to emulate that of a traditional literary scholar who reads a text, makes some annotations, compares and analyses the notes and then uses these results to interpret the text. [...] CATMA must also pay tribute to one of the key methodological tenets of literary scholarship: the principal open-endedness of any research into the semantics of literary texts.
- (aus dem Vorwort des CATMA Handbuchs, Schüch 2010).
Mit CATMA lassen sich Texte über Tags annotieren und in einem nächsten Arbeitsschritt bestimmte statistische Analysen über diese Annotationen auf einer intuitiv bedienbaren Benutzeroberfläche oder - abhängig von den Programmierkenntnissen des Anwenders - mithilfe eigener Anfragen rechnen.
Allgemeine Voraussetzungen
- Technische Voraussetzungen: Mac/Windows Betriebssystem und eine aktuelle JAVA-Version
- Aktuelle Version: CATMA 3.2
- Installationssoftware für Mac und Windows (JAVA basiert)
- kostenfreie Nutzung ohne Registrierung
- bearbeitet Dateien der Endung .txt, .doc, .pdf, .html, .htm und .rtf
- Nutzbar für Texte in über 45 Sprachen (Part of Speech-Trennung)
- Alle Ergebnisse können im .rtf-Format gespeichert werden
- Aufrufen von Hilfeseiten während der Bearbeitung möglich
- keine Programmierkenntnisse erforderlich
Detaillierte Beschreibung des Tools
Obwohl mit CATMA Kollokationsanalysen und Wortlisten generiert werden können, lebt das Tool von der händischen Annotation und der Expertise des Literaturwissenschaftlers, der sein Wissen an den Text heranträgt. In dieser Hinsicht ist es vergleichbar beispielsweise mit Scheherazade, das ebenfalls einen Fokus auf die qualitative Textanalyse legt. CATMA ist gleichzeitig allerdings in der Lage, statistische Analysen über händische Annotationen durchzuführen. Darin unterscheidet sich CATMA von den anderen in diesem Wiki vorgestellten Tools. Die drei interaktiven Komponenten des Tools sind<ref>www.catma.de/functionality</ref>:
- CATMA Tagger
- CATMA Analyzer
- Query Builder
Arbeitsschritte
Meine Beschreibung der einzelnen Arbeitsschritte in CATMA folgt in weiten Teilen dem englischsprachigen CATMA-Handbuch von Lena Schüch. Die Screenshots dienen nur der Illustration und zeigen die Mac-Distribution, ggf. kann sich die Oberfläche in Windows etwas anders darstellen.
-
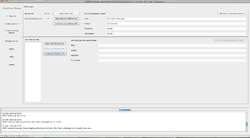 Startbildschirm des CATMA Taggers
Startbildschirm des CATMA Taggers

- Texteinspeisung: Das Source Document
- Um einen Text einzuspeisen, klickt man den Button Open Source File. Es lässt sich jede Datei mit einer der oben genannten Endungen von der Festplatte aus laden. Gleich darauf öffnet sich ein Dialogfenster, das den Nutzer bittet, eine mit dem Quelldokument assoziierte Structure Markup File zu öffnen oder erstellen zu lassen.
- Es können Einzeltexte mit den Endungen .doc, .txt, .pdf, .html, .htm und .rtf eingespeist werden.
- Eine Structure Markup File erstellen
-
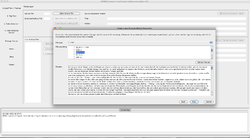 Eine neue Structure Markup-Datei anlegen
Eine neue Structure Markup-Datei anlegen

- In einem weiteren Schritt bittet CATMA den Benutzer, ein Structure Markup Document auszuwählen oder generieren zu lassen. In diesem Dokument speichert CATMA metatextuelle Informationen wie das Dateiformat, Textkodierung und die Sprache. Die Structure Markup-Datei erstellt CATMA automatisch, wenn an dieser Stelle "Create a new document" ausgewählt wird. Weiter wird CATMA dem ausgewählten Text in einem neuen Fenster ein Kodierungsformat zuweisen. Ob das Format richtig zugeordnet wurde, lässt sich überprüfen, indem man die Vorschau auf ausgetauschte Symbole durchsucht. Wird der Text korrekt angezeigt, hat CATMA das Textformat und die Kodierung richtig erkannt. Beides lässt sich auch manuell anpassen.
-
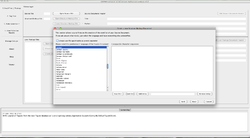 Sprache des Quelltextes festlegen
Sprache des Quelltextes festlegen

- In einem nächsten Schritt fragt CATMA nach der Sprache des Textes. Es lassen sich über 45 verschiedene Sprachen auswählen. Die Auswahl hilft CATMA, Wortarten korrekt zu trennen; beispielsweise sollte in einem englischsprachigen Text you'll als Kontraktion aus zwei Wörtern erkannt werden. Dazu lässt sich hier festlegen, wie CATMA das Apostroph behandeln soll. Weiter können manuell solche Einträge festgelegt werden, die nie getrennt dargestellt werden sollen. Es ist wichtig zu beachten, dass diese Auswahl sich nur ein Mal zu Beginn festlegen lässt und später nicht widerrufen oder verändert werden kann. Eine automatische POS-Erkennung liefert CATMA nicht.
- Optional kann dem Text danach Informationen zum Titel, Autor, Herausgeber und eine Beschreibung beigefügt werden. Zum Schluss fragt CATMA nach der Textsorte und bittet den Benutzer, zwischen Prose, Drama und Speech auszuwählen. Die Structure Markup-Datei spielt im weiteren Annotations- und Analyseprozess keine Rolle und wird automatisch gespeichert, wenn zum Schluss Create User Markup File angeklickt wird.
- Eine User Markup File erstellen
- Die User Markup File ist die Datei, in der CATMA Annotationen am Text speichert. So bleiben Markup und Originaltext getrennt und der Text wird im Analyseprozess nicht verändert. Das spielt besonders dann eine Rolle, wenn mehrere Parteien gleichzeitig an verschiedenen Markups zu einem Text arbeiten. Außerdem ist es so auch möglich, verschiedene Markup-Dateien mit einem Textdokument zu assoziieren, um den Überblick über die eigene Textarbeit zu behalten. Der Name des Markup-Dokuments kann dazu jeweils angepasst werden.