CATMA
Achtung: Hier entsteht ein Eintrag zu CATMA. Alle Inhalte sind noch vorläufiger Natur! :)'
Inhaltsverzeichnis
Kurzbeschreibung des Tools
CATMA steht für Computer Aided Textual Markup and Analysis. Es handelt sich dabei um ein Annotations- und Analysetool im Zeichen der empirischen Literaturwissenschaft. CATMA wurde für die literaturwissenschaftliche Analyse von Einzeltexten entwickelt und richtet sich speziell an Anwender mit wenig oder keinen Programmierkenntnissen.
Es kann in der aktuellen Version CATMA 3.2 kostenfrei heruntergeladen werden.
Die Software wird von einem Entwicklerteam an der Universität Hamburg laufend gewartet und weiterentwickelt. Der Projektleiter Jan Christoph Meister beschreibt das Arbeiten mit CATMA so:
- CATMA's workflow tries to emulate that of a traditional literary scholar who reads a text, makes some annotations, compares and analyses the notes and then uses these results to interpret the text. [...] CATMA must also pay tribute to one of the key methodological tenets of literary scholarship: the principal open-endedness of any research into the semantics of literary texts.
- (CATMA User Manual, Schüch 2010, S.3).
Mit CATMA lassen sich Texte über Tags annotieren und in einem nächsten Arbeitsschritt bestimmte statistische Analysen über diese Annotationen auf einer intuitiv bedienbaren Benutzeroberfläche oder - abhängig von den Programmierkenntnissen des Anwenders - mithilfe eigener Anfragen rechnen.
Allgemeine Voraussetzungen
- Technische Voraussetzungen: Mac/Windows Betriebssystem und eine aktuelle JAVA-Version
- Aktuelle Version: CATMA 3.2
- Installationssoftware für Mac und Windows (JAVA basiert)
- kostenfreie Nutzung ohne Registrierung
- Nutzbar für Texte in über 45 Sprachen (POS-Trennung)
- Alle Ergebnisse können im .rtf-Format gespeichert und bei Bedarf zu Voyeur exportiert werden
- Benutzerfreundliche englischsprachige GUI: keine Programmierkenntnisse erforderlich
- Aufrufen von Hilfeseiten während der Bearbeitung möglich
Detaillierte Beschreibung des Tools
Obwohl mit CATMA Kollokationsanalysen und Wortlisten generiert werden können, lebt das Tool von der händischen Annotation und der Expertise des Literaturwissenschaftlers, der sein Wissen an den Text heranträgt. In dieser Hinsicht ist es vergleichbar beispielsweise mit Scheherazade, das ebenfalls einen Fokus auf die qualitative Textanalyse legt. CATMA ist gleichzeitig allerdings in der Lage, statistische Analysen über händische Annotationen durchzuführen. Darin unterscheidet sich CATMA von den anderen in diesem Wiki vorgestellten Tools. Die drei interaktiven Komponenten des Tools sind<ref>www.catma.de/functionality</ref>:
- CATMA Tagger: Bereich für die Textarbeit mit Tags
- CATMA Analyzer: Bereich für die Analyse mithilfe automatisierter Verfahren
- Query Builder: GUI für Anfragen an den Text mithilfe regulärer Ausdrücke
Arbeitsschritte
Meine Beschreibung der einzelnen Arbeitsschritte in CATMA folgt in weiten Teilen dem englischsprachigen CATMA User Manual von Lena Schüch. Die Screenshots dienen als Anschauungsmaterial und zeigen die Oberfläche der Mac-Distribution, ggf. kann sie sich in Windows etwas anders darstellen.
-
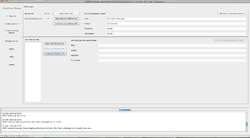 Startbildschirm des CATMA Taggers
Startbildschirm des CATMA Taggers

- Texteinspeisung: Das Source Document
- Um einen Text einzuspeisen, klickt man den Button Open Source File. Es lässt sich jede Datei mit einer der oben genannten Endungen von der Festplatte aus laden. Gleich darauf öffnet sich ein Dialogfenster, das den Nutzer bittet, eine mit dem Quelldokument assoziierte Structure Markup File zu öffnen oder erstellen zu lassen.
- Es können Einzeltexte mit den Endungen .doc, .txt, .pdf, .html, .htm und .rtf eingespeist werden.
- Eine Structure Markup File erstellen
-
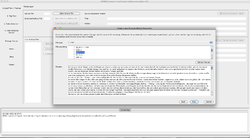 Eine neue Structure Markup-Datei anlegen
Eine neue Structure Markup-Datei anlegen

- In einem weiteren Schritt bittet CATMA den Benutzer, ein Structure Markup Document auszuwählen oder generieren zu lassen. In diesem Dokument speichert CATMA metatextuelle Informationen wie das Dateiformat, Textkodierung und die Sprache. Die Structure Markup-Datei erstellt CATMA automatisch, wenn an dieser Stelle "Create a new document" ausgewählt wird. Weiter wird CATMA dem ausgewählten Text in einem neuen Fenster ein Kodierungsformat zuweisen. Ob das Format richtig zugeordnet wurde, lässt sich überprüfen, indem man die Vorschau auf ausgetauschte Symbole durchsucht. Wird der Text korrekt angezeigt, hat CATMA das Textformat und die Kodierung richtig erkannt. Beides lässt sich auch manuell anpassen.
-
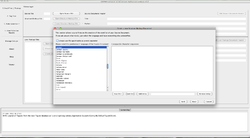 Sprache des Quelltextes festlegen
Sprache des Quelltextes festlegen

- In einem nächsten Schritt fragt CATMA nach der Sprache des Textes. Es lassen sich über 45 verschiedene Sprachen auswählen. Die Auswahl hilft CATMA, Wortarten korrekt zu trennen; beispielsweise sollte in einem englischsprachigen Text you'll als Kontraktion aus zwei Wörtern erkannt werden. Dazu lässt sich hier festlegen, wie CATMA das Apostroph behandeln soll. Weiter können manuell solche Einträge festgelegt werden, die nie getrennt dargestellt werden sollen. Es ist wichtig zu beachten, dass diese Auswahl sich nur ein Mal zu Beginn festlegen lässt und später nicht widerrufen oder verändert werden kann. Eine automatische POS-Erkennung liefert CATMA nicht.
- Optional kann dem Text danach Informationen zum Titel, Autor, Herausgeber und eine Beschreibung beigefügt werden. Zum Schluss fragt CATMA nach der Textsorte und bittet den Benutzer, zwischen Prose, Drama und Speech auszuwählen. Die Structure Markup-Datei spielt im weiteren Annotations- und Analyseprozess keine Rolle und wird automatisch gespeichert, wenn zum Schluss Create User Markup File angeklickt wird.
- Eine User Markup File erstellen
- Die User Markup File ist die Datei, in der CATMA Annotationen am Text speichert. So bleiben Markup und Originaltext getrennt und der Text wird im Analyseprozess nicht verändert. Das spielt besonders dann eine Rolle, wenn mehrere Parteien gleichzeitig an verschiedenen Markups zu einem Text arbeiten. Außerdem ist es so auch möglich, verschiedene Markup-Dateien mit einem Textdokument zu assoziieren, um den Überblick über die eigene Textarbeit zu behalten. Der Name des Markup-Dokuments kann dazu jeweils angepasst werden.
- Den Text taggen
- Einzelne Textstellen taggen
- Ein Text wird in CATMA über so genannte "Tags" annotiert. Tags sind im Wesentlichen digitale Unterstreichungen, die je nach Fragestellung entweder an einzelnen Wörtern oder an ganzen Absätzen vorgenommen werden können. Eine mögliche Vorgehensweise ist dabei, den Text mit gedrückter linker Maustaste zu markieren und dann mit einem rechten Mausklick Create Tag auszuwählen.
-
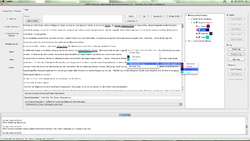 Den Text taggen
Den Text taggen
-

- In einem weiteren Dialogfenster bittet CATMA den Benutzer automatisch, einen Namen für den Tag anzulegen und ihm eine Farbe zuzuweisen. Außerdem muss dem neuen Tag ein Platz in der Hierarchie eines Tag-Sets zugewiesen werden. Standardmäßig lässt sich der neue Tag unter dem Standard Tagset einordnen. Alternativ können die gewünschten Tagsets auch vor dem Taggen festgelegt werden. Ein so erstellter Tag lässt sich danach auf jeden markierten Textteil übertragen, wobei sich Tags auch teilweise oder vollständig überschneiden dürfen. Im Folgenden wird erläutert, wie bestimmte händische Arbeitsschritte durch korpusanalytische Suchverfahren ersetzt werden können, indem mehrere Instanzen eines Ausdrucks über die Suchfunktion getaggt werden.
- Mehrere Instanzen eines Ausdrucks taggen
- Über die Suchfunktion kann CATMA mehrere Instanzen eines Ausdrucks gleichzeitig taggen. Dazu gibt man in der Suchmaske unter Berücksichtigung von Groß- und Kleinschreibung den Suchbegriff ein. Alle Instanzen des gesuchten Ausdrucks werden dabei markiert. Über die Buttons Down und Up lässt sich der Text händisch nach den markierten Abschnitten durchsuchen. Nach einem Klick auf Tag results öffnet sich ein separates Dialogfenster, in dem alle markierten Instanzen im Text als KWIC dargestellt werden. Hier lassen sich händisch einzelne Resultate aus der Suche ausschließen und im Anschluss alle gewünschten Funde mit einem vorher definierten Tag belegen.
- Achtung: Es lassen sich über die Suchfunktion nur Resultate mit einem zuvor definierten Tag belegen!
- Tags können mithilfe der Buttons rechts neben dem Fenster mit der Tag-Baumstruktur nachbearbeitet werden. Es ist beispielsweise möglich, dem Tag Eigenschaften zuzuweisen. Diese bestehen im Wesentlichen in einer Beschreibung des jeweiligen Tags. Des Weiteren können hier Farben und Namen von Tags geändert und ganze Tagsets gelöscht werden.
Mögliche Analysen
CATMA bietet mehrere mögliche Analyseschritte an, die sich über die GUI ausführen lassen. Für diese sind keine Programmierkenntnisse erforderlich; weiter unten wird aber deutlich, dass schon Basiswissen über reguläre Ausdrücke komplexere Anfragen möglich macht und CATMA zu einem mächtigeren Werkzeug wird, wenn der Anwender selbst Anfragen programmieren kann.
- Wortlisten
- CATMA erstellt auf Anfrage Wortlisten, mit denen verschiedene Operationen ausgeführt werden können. Um die Wortliste anzuzeigen, wählt man in der linken Spalte 3. Make Selection und dann from Wordlist aus. Per default sortiert CATMA alle Einzelwörter des Quelltextes absteigend nach ihrer Frequenz. Genau wie nach Einzelwörtern kann dabei auch nach Tags durchsucht werden. Mit diesen können im Wesentlichen drei Operationen durchgeführt werden: Kollokations- und Distributionsanalysen und in deren Zusammenhand auch KWIC-Analysen.
- Kollokationsanalyse
- Mit CATMA kann nach solchen Wörtern gesucht werden, die sich in unmittelbarer Nachbarschaft zu ausgewählten Wörtern oder Tags befinden. Dazu müssen in der Make Selection-Ansicht die entsprechenden Einträge ausgewählt werden und die Box links neben dem Befehl compute Collocation Analysis angetickt werden. Mit einem Klick auf Update Selection and View Results zeigt CATMA die Wörter in unmittelbarer Nachbarschaft zum Zieleintrag an.
-
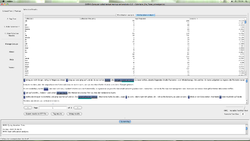 Kollokationsanalysen mit CATMA
Kollokationsanalysen mit CATMA

- Das gehäufte Auftreten solcher Nachbarschaften von Wörtern wird in der Linguistik als Kollokation bezeichnet. CATMA berechnet die Kollokationsfrequenz als absolute Menge der Vorkommnisse zweier Wörter im Quelltext. Gleichzeitig wird jeweils die statistische Wahrscheinlichkeit, dass eine Kollokation im Text nicht zufällig auftritt, als z-score angegeben. Zur ersten Orientierung: Je höher der z-score, entweder positiv oder negativ, desto wahrscheinlicher ist es, dass die Kollokation im Text auftritt.
- Unten rechts im Kollokationsanalysefenster befindet sich ein Regler, mit dessen Hilfe zwischen einer KWIC-Ansicht, einer variablen Textansicht (d.h., im Kontext einer veränderbaren Anzahl von Wörtern rechts und links vom Zieleintrag) oder dem Volltext gewechselt werden kann.
- Verteilungsanalyse
- CATMA kann die Verteilung eins oder mehrerer ausgewählter Wörter oder Tags im Quelltext als Graph anzeigen. Um diese Verteilungsanalyse anzuzeigen, geht man wiederum, wie bei der Kollokationsanalyse, von der Wortliste aus und tickt die Box links neben dem Befehl Compute Distribution Analysis an. Weiter lässt sich die Größe der chunks, also der bei der Berechnung der Verteilung berücksichtigten Wortgruppen, variabel einstellen. Als zielführend hat sich eine Einteilung in 10\%-chunks erwiesen, da eine feinere Gliederung dazu führt, dass sich keine sichtbaren Verteilungen über den Text ausmachen lassen, sondern lediglich punktuelle Vorkommnisse.
-
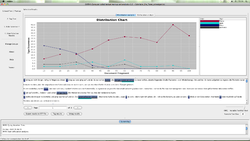 Distributionanalysen mit CATMA
Distributionanalysen mit CATMA

- Im vorliegenden Beispiel wurde eine Anfrage mithilfe des CATMA QueryBuilders gestellt, die die Verteilung getaggter Instanzen im Quelltext betrifft, nicht die von einzelnen Wörtern. Das heißt, mit dem Query Builder lässt sich der Text über die Wortliste hinaus auch im Hinblick Tags analysieren. Wie der QueryBuilder dem programmierunerfahrenen Anwender dabei hilft, wird im Folgenden erläutert.
- Komplexe Anfragen: Der CATMA QueryBuilder
-
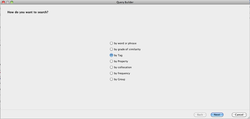 Der CATMA QueryBuilder
Der CATMA QueryBuilder

- Über die oben vorgestellten Analysen hinaus lassen sich eine Vielzahl komplexer Anfragen an den Text stellen, für die Anwender ohne Programmierkenntnisse den so genannten QueryBuilder nutzen können. Er ist also im Wesentlichen eine graphische Oberfläche für das Ausführen komplexerer Operationen. Mit einem Klick auf den Button QueryBuilder unterhalb der Eingabemaske für Queries öffnet sich ein neues Fenster, welches nach der gewünschten Auswahl fragt. Es lässt sich beispielsweise eine Suche nach Einzelwörtern und Tags kombinieren sowie unerwünschte Einträge aus der Auswahl ausschließen. Damit können Distributions- und Kollokationsanalysen über mehrere Wortgruppen und/oder Tags angezeigt werden (siehe auch Anwendungsbeispiel).
-
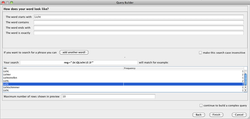 Suche nach Einzelwörtern mit dem QueryBuilder
Suche nach Einzelwörtern mit dem QueryBuilder

- Der QueryBuilder erstellt nach den Angaben auf der GUI die Anfrage automatisch, welche zum Schluss in der Eingabemaske für Queries in der Tagging-Ansicht angezeigt wird. In dieser Eingabemaske lassen sich die Anfragen im Anschluss auch modifizieren. Als besonders nützlich erweist sich an dieser Stelle das CATMA User Manual, welches ab S. 46 die Query-Syntax im Detail anhand von Beispielen erklärt.
- Mit dem QueryBuilder und der Kollokations- und Distributionsanalyse wurden in diesem Abschnitt die wesentlichen Funktionalitäten von CATMA erläutert und anhand von Screenshots das jeweilige Vorgehen beim Taggen und der anschließenden Analyse erklärt. Im Folgenden soll ein Beispiel gegeben werden, wie die empirische Analyse eines literarischen Textes mit CATMA aussehen könnte, bevor zum Schluss auf Probleme eingegangen wird.