Scheherazade
| Unser LitRe-Wiki ist seit 2012 nicht eingreifend überarbeitet worden. Es bildet also den damaligen Stand ab. Um Weiterentwicklungen der digitalen Textanalyse abzubilden, sollen nun die Artikel peu à peu überarbeitet werden, und weitere Artikel hinzukommen.
Interesse? Haben Sie Lust, einen Artikel zu überarbeiten oder neu zu verfassen? Schreiben Sie uns! Auch Kommentare, Kritik oder Fragen sind willkommen: mailto:bherrma1@gwdg.de |
Bei Scheherazade handelt es sich um ein Tool zur semantischen Annotation und Codierung von Geschichten. Der Kern der Software sind Datenbanken, die es ermöglichen, logische Repräsentationen von Inhalten darzustellen. Das Ergebnis der Codierung ist ein Story Graph. Entwickelt wurde das Programm von David K. Elson während seiner Zeit als PhD-Student in der Natural Language Processing Group der University of Columbia.
Scheherazade steht kostenlos zum Download zur Verfügung: Scheherazadev0.33
Das Tool soll die Analyse von narrativen Strukturen und Inhalten erleichtern. Methodologisch arbeitet das Tool stark inhaltlich fokussiert und soll helfen, auf Einzeltextebene natürliche Sprache zu beschreiben. Insofern ist es in das Gebiet des natural language processing einzuordnen. Die Arbeits- und Analyseschritte sind qualitativ und händisch vorzunehmen.
Inhaltsverzeichnis
Allgemeine Voraussetzungen
- Technische Voraussetzungen: Mind. 1 GB RAM Arbeitsspeicher und eine aktuelle Java-Version.
- Die Software kann als zip-Datei auf den eigenen Rechner geladen und von dort entpackt und gestartet werden (BAT-Datei).
- Der Download ist kostenlos und auch ohne Registrierung möglich. Zusätzlich steht eine Beispielanalyse zum Download zur Verfügung.
- Das Programm verfügt über ein graphisches Interface und auch über ein Javadoc für Entwickler.
- Bei der hier beschriebenen Version handelt es sich um Scheherazade v0.33 vom März 2011 für Linux, MAC und Windows. Dabei handelt es sich um eine Beta-Version (initial release 2007).
- Der Entwickler übernimmt keine Garantien, da sich das Programm noch im Aufbau befindet und lediglich für Demo-Zwecke lizensiert ist.
- Die Datenspeicherung erfolgt auf der eigenen Festplatte im VGL-Format.
- Die derzeitige Version beinhaltet ein bereits integriertes Äsop-Korpus, man kann jedoch jede beliebige TXT-Datei einlesen.
- Bei selbsteingelesenen Texten ist keine Vorannotierung nötig, die Annotierung erfolgt während der Berarbeitung im Programm (vgl. CATMA).
- Um die Vergleichbarkeit und Interpretierbarkeit der Ergebnisse zu gewährleisten, erfolgt die Annotation auf der Basis der Datenbanken WordNet (Release 3.0 Princton University 2006) und VerbNet (Release 2.3 University of Colorado 2006).
- Da die Datenbanken englischsprachig sind, ist auch die Annotation nur englischsprachig möglich.
Detaillierte Beschreibung des Tools
Der Story-Graph-Ansatz
Kern des Tools ist es, eine Gesamtanalyse einer Geschichte zu ermöglichen bzw. den wesentlichen Plot der gesamten Geschichte in einem einzigen Story Graph darzustellen. Mindmapartig kodiert dieser Story Graph den gesamten Plot mit Hilfe von Knoten und Bögen. Die Knoten stehen dabei für Objekte und Aktionen, Bögen repräsentieren textuelle Verbindungen wie Chronologie oder Kausalität. Ziel dieses Ansatzes ist es, einen holistischen Blick auf den Text zu ermöglichen und im Überblick das Zusammenspiels der einzelnen Fakoren und die Funktionsweise der Geschichte analysieren zu können.
Die aktuelle Version von Scheherazade beeinhaltet neben dem stated layer, welches eine rein textbasierte Darstellung liefert, zusätzlich die Möglichkeit, ein interpretative layer in den Story Graph zu integrieren. Dort lassen sich Interpretationen, nicht-versprachlichte Ziele und Wünsche von Figuren etc. darstellen.

Arbeitsschritte
- Dateneinspeisung
- Beim Starten des Programms gibt es zunächst drei Möglichkeiten, Daten einzuspeisen: Es lassen sich bereits annotierte Texte bzw. bereits erstellte Graphen einlesen. Hierzu betätigt man den Load Encoding Button und wählt eine VGL-Datei von der eigenen Festplatte aus. Des Weiteren lassen sich verschiedene Fabeln des integrierten Äsop-Korpus oder eigene TXT-Dateien zur eigenen Annotation laden.
- Annotation
- Voraussetzung für die Erstellung eines Story Graphs eines jeden Textes ist es, dass der Annotator den Text gelesen und verstanden hat sowie einen Überblick über die zentralen Akteure, Themen und Prozesse hat. Nun beginnt die eigentliche Annotationsarbeit. Elson und McKeown (2010) [1] teilen die Annotation in drei Schritte ein: Object extraction, Construction of propositions und Assignment and linking. Die folgende Beschreibung lehnt sich in den Grundzügen daran an.
- Objekte benennen
- Nachdem man einen noch unbearbeiteten Text eingelesen hat, erscheint dieser im Original-Story-Fenster. In der Ansicht Story Elements definiert man nun die zentralen Figuren, Handelnden und Motive. Hierzu wählt man den jeweiligen Reiter aus für Characters, Locations, Props, Qualities und Behaviors. Im entsprechenden Reiter gibt man im Suchfenster von WordNet den Namen der zu benennenden Entität (z.B. fox) ein, wählt einen der durch die Datenbank unterbreiteten Vorschläge aus und bestätigt diesen per Mausklick. Das benannte Objekt erscheint nun als Defined Character. So verfährt man mit allen weiteren zu benennenden Entitäten.

- Relationen herstellen und Textstellen zuweisen
- Im nächsten Schritt erstellt man die Story Line in der Timeline-Ansicht. Hier gibt man Schritt für Schritt einzelne Propositionen an und verbindet diese mit den entsprechenden Textstellen. Hierzu erstellt man einzelne Story Points auf der Story Line, markiert in der Ansicht der Original Story die entsprechende Textstelle und wählt nun mit Hilfe von VerbNet die entsprechenden Prädikate und Argumente aus, die die Textstelle am geeignetsten wiedergeben.

Das Panel von VerbNet ändert sich je nach der thematischen Rolle des ausgewählten Arguments. Die Proposition bestätigt man mit Klick auf den entsprechenden Button. Das textuelle Ergebnis dieser Annotation findet sich im Fenster der Reconstructed Story. Dies dient der Überprüfung der Annotation. Da sich die ursprüngliche Story und die Rekonstruktion direkt übereinander befinden, lässt sich das Ergebnis leicht überprüfen.

- Interpretation
- Aufbauend auf den getätigten Annotationsschritten, erstellt das Programm nun den entsprechenden Story Graph. Diesen kann man sich über die Interpretations-Ansicht anzeigen lassen. Dabei ist es während der Annotation wichtig, sich zu vergegenwärtigen, dass die einzelnen Elemente des Story Graphs nicht einzelne Sätze veranschaulichen, sondern inhaltliche Einheiten. Wie groß diese Einheiten sind und wie viel Inhalt sie jeweils abbilden, entscheidet der Annotator. In der Graphen-Ansicht beinhalten die rosa hinterlegten Felder die markierten Teile des Ursprungstextes. Die hellblau hinterlegten Felder beinhalten die Propositionen der Rekonstruktion, die in der Story Line erstellt wurden. Rechts daneben lässt sich noch das Interpretative Layer einfügen.
- Die Elemente des Story Graphs lassen sich frei auf dem Workspace verschieben. Die Bögen können nun modifiziert werden, z.B. kann angegeben werden, welche Verbindungen für tatsächliche Ereignisse stehen, welche für rein hypothetische oder welche z.B. Kausalitäten beschreiben.
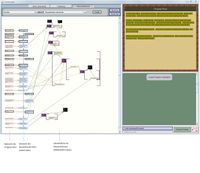 Abb. 5 Story Graph
Abb. 5 Story Graph
- Die Elemente des Story Graphs lassen sich frei auf dem Workspace verschieben. Die Bögen können nun modifiziert werden, z.B. kann angegeben werden, welche Verbindungen für tatsächliche Ereignisse stehen, welche für rein hypothetische oder welche z.B. Kausalitäten beschreiben.
- Art der Analyse
- Die Art der Analyse ist rein qualitativ. Das Ergebnis der Annotation hängt maßgeblich vom Annotator ab. Obwohl man sich nach den Vorgaben der Datenbanken richten muss, sind doch immer verschiedene Annotationsmöglichkeiten gegeben, die auch für das Aussehen des Story Graphs entscheidend sind. Für einen Text können demnach verschiedene Annotatoren zu verschiedenen Ergebnis-Graphen kommen.
- Vergleiche von verschiedenen Texten sind im Programm nicht möglich. Jedoch ist es praktikabel, verschiedene Texte in Ergebnis-Graphen abzubilden, die Graphen in anderen Formaten zu speichern und diese dann zu vergleichen.
- Ausgabedaten
- Das Ausgabeergebnis von Scheherazade ist der Story Graph. Eine einfache Möglichkeit, den Ergebnis-Graphen zu sichern und für andere Programme verarbeitbar zu machen, besteht darin, diesen mittels Screenshot in ein anderes Dateiformat zu übertragen. Die Speicherung der Daten erfolgt über das Control Panel.
Benutzerfreundlichkeit und Transparenz
Benutzerfreundlichkeit
Die Zielgruppe von Scheherazade sind Literaturwissenschaftler. Für Neueinsteiger ist das Tool aufgrund des graphischen Interfaces nutzbar. Ohne Programmierkenntnisse sind auf der Oberfläche nur bedingt kreative Anfragen möglich. Das Umgehen der Datenbanken ist möglich, behindert aber die Umsetzung des Plots im Story Graph und wirkt der Vergleichbarkeit verschiedener Graphen entgegen. Eine Hilfefunktion steht leider nicht zur Verfügung . Als Anleitung diente hier das Paper von Elson und McKeown (2010) [1]. Detailliertere Anwendungsfragen wurden durch Ausprobieren erschlossen. Da neben dem Button für das Control Panel ein Hilfe-Button angelegt ist, ist davon auszugehen, dass die endgültige Version über ein Hilfe-Menü verfügen wird.
(Anmerkung August 2015: inzwischen gibt es ein Tutorial: https://sites.google.com/site/scheherazadetutorial/)
Transparenz
Der Quellcode des Tools ist sichtbar. Programmdetails können eingesehen werden. Die Release History sowie Lizenzinformationen etc. werden im Readme angegeben. Hier schränkt Elson selbst die Zuverlässigkeit des Tools ein und betont, dass die Entwicklung noch in progress sei. Elsons Mailadresse ist angegeben und er bietet Unterstützung bei Forschungsfragen an. Da er den Entwicklungsprozess von Scheherazade im besprochenen Artikel auch durchaus kritisch betrachtet, ist davon auszugehen, dass Feedback erwünscht ist. In Ausblick stellt er eine Erweiterung des Äsop- Korpus, die Einbeziehung zeitgenössischer Genres, den Ausbau des Interfaces sowie die Ausweitung des Interpretative Layers.
Fazit
Bei Scheherazade handelt es sich um ein Tool zur Beschreibung bzw. Abbildung der Gesamtstruktur eines Textes mit seinen relevanten semantischen Prozessen. Dabei geht der Fokus weg von der Lexik hin zu tieferliegenden Prozessen im Text. Der vom Programm generierte Story Graph ist ein statisches Modell des gesamten Textes. Die Annotation erfolgt in einem dynamischen Prozess, d.h. man kann zwischen den einzelnen Annotationsschritten bei Bedarf wechseln.
Probleme der Analyse durch Scheherazade, die Elson z.T. auch selbst anspricht sind z.B., dass Wortbedeutungen stets desambiguiert werden müssen, Koreferenz muss selbst gezogen werden, Zeitformen müssen selbst interpretiert und Handlungen angeordnet werden. Eine Interpretation der Geschichte muss durch den Annotator erfolgen und ist für den Aufbau des Graphen essentiell. Der Story Graph ist somit ein notwendig subjektives Ergebnis. Zudem kann nur dargestellt werden, was auch im Text verschriftlicht ist. Ist also z.B. die Moral der Fabel nicht niedergeschrieben, so kann sie auch nicht im Story Graph dargestellt werden. Einen Ansatz zur Lösung dieses Problems bietet das Interpretative Layer. Bei der Annotation ist es sinnvoll zu simplifizieren, um die Übersichtlichkeit des Graphen hoch zu halten. Problematisch ist die Darstellung von Passiv, von Adjektiven und Adverben und Ähnlichem. Hier ist es wichtig, zu überlegen, welche Textelemente wirklich essentiell für den Text sind. Idiome und stilistische Mittel lassen sich gar nicht darstellen. Es zeigt sich, dass der Annotationsprozess den Annotator zu konzeptueller Schärfe und Konsistenz zwingt. Ziel ist die Darstellung des Inhalts, nicht der Rhetorik.
Der Zeitaufwand der Annotation ist stark vom Text abhängig, aber tendentiell hoch, da es sich um ein qualitativ arbeitendes Tool handelt. Hinzu kommt der Zeitaufwand, den Text im Vorfeld zu lesen und zu interpretieren. Bei einer Studie zum Vergleich von Story Graphs verschiedener Äsop-Fabeln gibt Elson eine Durchschnittsbearbeitungszeit der Annotatoren von 45 Minuten pro Fabel an, bei 9 Wörtern je dargestellter Proposition.
Der Interpretationsspielraum der Ergebnisse ist eher gering.Die Zuverlässigkeit des Ergebnisses hängt maßgeblich von der Zuverlässigkeit des Annotators ab. Wissenschaftliches Arbeiten mit Scheherazade bewegt sich eher auf explorativer Ebene. Für quantitative Fragen sind oberflächenstrukturell arbeitende Tools besser geeignet. Quantitative, semantische Phänomene sind schwieriger zu operationalisieren. Und auch bei den durch Scheherazade unternommenen Versuchen, sich diesem Problem anzunähern, ist der händische Aufwand noch ausschlaggebend und nicht zu unterschätzen. Auf jeden Fall fordert die Vorarbeit bzw. die Annotation des zu analysierenden Textes konzeptuelle Schärfe und Konsistenz vom Forschenden. Vor jedem Analyseschritt ist es unerlässlich, die entsprechende Proposition zu konzeptualisieren und zu operationalisieren. Außerdem muss jede Proposition mit ihrem Stellenwert im Gesamtplot problematisiert werden. Die Hauptleistung des Tools liegt vielleicht sogar auf den durch den Annotationsprozess initiierten Überlegungen des Annotators. Durch den Prozess des Annotierens wird der Forscher zu derart detaillierter Durchdringung des Forschungsgegenstandes gezwungen, dass damit u.U. schon das gewünschte Analyseergebnis zu Tage gefördert wird. Der Story Graph ist dann vielmehr ein Abbild des Annotations- und Analyseprozesses.
Elson bringt die Leistung des Tools selbst folgendermaßen auf den Punkt: "A story graph becomes more a model of the received story than an absolute record of the story content." (Elson/McKeown 2010:7) [1]
Beispielanwendung
Bei der Analyse von Texten mit Hilfe von Scheherazade ist es wichtig, im Vorfeld Erwartungen an eine Analyse zu konkretisieren. Mitunter kann es sinnvoll sein, nur bestimmte Teile eines Textes abzubilden. Das von Elson untersuchte Äsop-Korpus legt Vergleichsanalysen mit Hilfe von Scheherazade nahe. So lassen sich parallele Sturkturen in Fabeln aufdecken. Wenn man eine genügend große Zahl an Fabeln durch Story Graphs abbildet, sollte sich zeigen, dass alle einem ähnlichen Schema folgen. Da Fabeln typische Schema-Literatur sind, wäre das auch eine interessante Anwendungsmöglichkeit für die Schule. Dabei ist höchstwahrscheinlich nicht der Annotationsprozess selbst eine geeignete Aufgabe für Schüler, sonder der Vergleich bereits erstellter Graphen. Für die Wissenschaft ist denkbar, dass man bestimmte Teile von Werken einer Epoche, eines Autors oder einer Gattung zu vergleichen. Zum Beispiel könnte man den Anfang von mehreren realistischen Novellen analysieren und überprüfen, ob diese Ähnlichkeiten in der Konstruktion aufweisen.
Abseits von Korpusstudien bietet sich Scheherazade vorrangig für Einzeltextanalysen an. Je nach Textlänge und Forschungsinteresse ist die Frage, wie detailliert ein Text abzubilden ist, ob er als Gesamttext abgebildet werden soll etc. Da die Story Line vom Annotator selbst angegeben wird, ist es durchaus sinnvoll, bei längeren Texten Schwerpunkte zu legen und sich zum Beispiel nur auf den Erzählstandpunkt und den Perspektivwechsel zu konzentrieren, um dem zugrunde liegende Strukturen aufzudecken und darzustellen. Man könnte auch einen Text auswählen, komplett annotieren und anhand des Story Graphs nach interessanten Strukturen suchen.
Als Analyse-Beispiel ist hier "Großer Lärm" [2] von Franz Kafka ausgewählt. Der Text bietet sich für eine Analyse durch Scheherazade an, da er relativ kurz und durch lange Schachtelsätze inhaltlich unübersichtlich ist. Eine Frage an die Analyse könnte sein: Wie wird der Eindruck von Unruhe und Unbehaglichkeit erzeugt? Schnell kristallisiert sich die strukturgebende Erzählperspektive des Ich-Erzählers heraus, um den sich das gesamte Geschehen dreht. Bei der linearen Anordnung der Propositionen auf der Story Line und später im Story Graph zeigt sich, dass sich die Mehrzahl der Propositionen auf der Ebene der Gleichzeitigkeit befinden und keine primär fortschreitende Handlung stattfindet. Dieses Nebeneinander von geräuschintensiven Argumenten wie "Laufenden", "Zuklappen" oder "Herdtüre" zeigt sich als Indiz für den sich dem Rezipienten ergebenden Eindruck der nervösenn Unbehaglichkeit des Textes. Die einzige Textstelle an der tatsächlich eine die Textwelt ändernde Handlung einsetzt, ist das Verlassen der Wohnung durch den Vaters. Durch die Art der Bögen wird dies im Story Graph deutlich. An der gefühlten Situation ändert diese Handlung jedoch nichts. Ebenso lässt sich im Story Graph abbilden, dass es sich beim Schlusssatz um ein hypothetisches Gedankenspiel handelt, welches in der Form ebenfalls nichts an der Situation des Erzählers ändert.
Was durch die Analyse durch Scheherazade nicht zu Tage gefördert wird, ist die Kriegs-Lexik ("Hauptquartier", "kriechen"), da man in der semantischen Darstellung vermutlich auf eine andere Lexik zurückgreifen müsste. Ein ebenfalls wichtiger Unruhe-Faktor ist die hypotaxe Satzstruktur sowie die enorme Länge der Sätze, die eine hohe Aufmerksamkeitsspanne beim Lesen erfordern. Dies würde ebenfalls nicht durch Scheherazade zu Tage gefördert werden, da die Propositionen unabhängig von Satzgrenzen dargestellt werden. Den Stellenwert der Adjektive muss der Annotator selbst bestimmen, in dem er sich für oder gegen ihre Darstellung entscheidet.
Diese Betrachtung einer möglichen Analyse von Kafkas Text durch Scheherazade wurde rein hypothetisch unternommen. Das Problem einer tatsächlichen Annotation liegt in der Sprachbarriere. Die Scheherazade zugrundeliegenden Datenbanken bilden die englische Sprache ab. Eine Annotation ohne die Datenbanken schränkt die Vergleichbarkeit und Interpretierbarkeit der abgebildeten Sprache ein und entzieht dem Story Graph eine wichtige Interpretationsgrundlage, da der semantischen Darstellung die konsensuelle Grundlage entzogen ist. Theoretisch ist es möglich, einen Text in einer anderen Sprache zu annotieren, d.h. einen deutschen Text mit englischen Argumenten zu verbinden, da die Verbindung zwischen Ursprungstext und semantischer Darstellung ausschließlich durch de Annotator hergestellt wird. Bei literarischen Texten, die per Definition durch ihren ästhetischen Wert Analysegegenstand sind, ist dies kritisch. Bestimmte Strukturen sind sprachgebunen und eine Übersetzung wäre notwendigerweise subjektiv gefärbt und würde den Originaltext verfälschen. Für das reine Lesevergnügen mag das akzeptabel sein, für eine wissenschaftliche Analyse nicht. Demzufolge ist Scheherazade ein Tool, welches in der Form hauptsächlich in der Anglistik Anwendung findet.
Literatur
[1] Elson, David K., McKeown, Kathleen R. (2010): Building a Bank of Semantically Encoded Narratives. LREC Malta, 17.-23.05.2010. New York City. Online im Internet: URL: http://www1.cs.columbia.edu/~delson/pubs/LREC2010-ElsonMcKeown.pdf (16.02.2012).
[2] Kafka, Franz (1912): Großer Lärm. In: Nervi, Mauro (2011): The Kafka Project. Online im Internet: URL: http://www.kafka.org/index.php?laerm (16.02.2012).
Weblinks
- David K. Elson: http://www1.cs.columbia.edu/~delson/index.shtml
- Scheherazade v0.33: http://www1.cs.columbia.edu/~delson/software.shtml
- WordNet: http://wordnet.princeton.edu/
- VerbNet: http://verbs.colorado.edu/~mpalmer/projects/verbnet.html